In computer science a distributed system is a software system in which different parts of it communicate by passing messages through a network. The different parts could be running in the same machine or distributed across the globe; as long as they communicate through an unreliable channel (a network), we can classify them as distributed and consider the challenges that come with it.
With this definition in mind, we could think about many examples of distributed systems. A single monolithic application communicating with a database could be considered a distributed system if the application communicates through a network protocol.
Although in practice, local networks can be pretty reliable, they are still vulnerable. There are two condition that can cause a plethora of problems to a system: the network being down or the network being slow. These two conditions can put the system in a wide variety of states that may give results we don’t expect.
Before we look at how these problems can affect a distributed system, lets look at a distributed system whose failure mode is mostly understood and accepted to this date: a stateless system.
Stateless system
With our definition of a stateless system above. Lets create a distributed system that doesn’t hold any state. A good example of this could be a static files server. In this system, you will get a file back when you request a URL. The system doesn’t care about anything else, when it receives the request it will return the file without asking any questions or doing any calculations. To make this a distributed system, lets put a load balancer before our server:

The failure modes for this system are very simple. If the network is down, we won’t be able to serve the static file. There is really nothing we can do about this. If the network is slow, the file will take a long time to get transferred. This might result in a timeout in any part of the system: The requester, the load balancer or the static files server.
What can we do when we notice a failure? The only thing we can do is to figure out why our network is failing and try to fix it. The time it takes for the issue to be fixed might result in downtime, but at the time the system comes back up, everything will start working as expected.
Stateful system
Stateful systems add a new dimension of problems that have been subject to a lot of research lately. The problem with stateful systems is that if they fail in certain ways, they could end up in an inconsistent state. Depending on the kind of system, this could be catastrophic.
Lets look at a simple stateful system first:
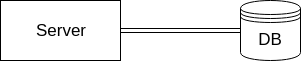
This system has a database where state can be saved. Although this is a distributed system, our state management is centralized. Most likely our first approach to scaling this system would be to add another server, but keep using a single DB.
Having a single point where state is managed is a very common solution for many systems. Since this is such a mature configuration, the failure modes are pretty well known:
- Network down: Can’t communicate with DB, so we can’t save or retrieve state. Return an error
- Network slow: Takes long for state to be retrieved or saved. Wait for the request to finish or timeout
I’m just focusing on the conditions that can result because of network issues, because these are specific to my definition of distributed system. There are other problems (hardware or software) that could happen, but I’m not going to talk too much about them (from the consumer perspective, it might look as if the network was misbehaving).
If you are paranoid, you might feel uneasy about the network slow failure mode. Specially in the scenario where we are trying to save to the database. The truth is that it is possible that a request is sent to the DB and the DB processes it, but then the response doesn’t reach the consumer. This means the state transition actually took place, but the consumer thinks it didn’t. This is a very interesting situation, that could anger the consumers of the system, but from the database and system perspective, nothing catastrophic has happened.
Lets look at a specific scenario of this failure. Lets assume the system allows people to transfer money to other people:
- Jose sends money to Carlos
- System receives the request and sends it to the database
- Database saves the transaction (money deducted from Jose and credited to Carlos)
- The query to the database takes too long and the server times out sending an error to Jose
- Jose sees the error and tries to send money to Carlos again
- System receives the request and sends it to the database
- Database saves the transaction (money deducted from Jose and credited to Carlos)
- A success message is sent to Jose
In the example above, the system is in a perfectly valid state. Jose made two money transfers to Carlos. From Jose’s point of view, he made only one transfer to Carlos. He might in a future time look at his statement with disgust when he discovers that the transfer actually happened two times.
With the unreliability of networks in play, these kind of problems are very hard to solve. If this happened in real life, most likely Jose would call the system providers and demand this to be corrected. The system owners will notice the problem and do the correction (There are techniques to prevent this from happening too often, but I’m not going to cover those here).
Distributed state
If we continue on the distributed systems path, we will encounter systems where the state is also distributed. The reason for this could be because we want to provide fault tolerance (if one database goes down we can use the other one) or scalability (One machine can’t take the load so we split it).
Lets look at an example system that uses distributed state to achieve scalability. It uses an asynchronous database replica for reads, this way reducing the load on the main database:
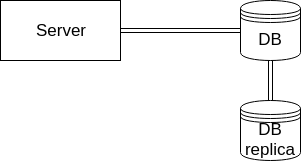
This system has all the same issues as the example with a centralized database with some extra problems of its own. Since the state is replicated asynchronously from the master DB to the Replica, it takes some time for state to propagate from one to the other. The amount of time it takes to replicate varies a lot, but it could be very large if the system is very busy.
Lets look at an new kind of situation we might find in this configuration:
- Jose sends money to Carlos
- System receives the request and sends it to the database (Master, since it’s a write)
- Database (Master) saves the transaction
- Jose sees a success message
- Jose goes to the transaction history page
- System receives the request and sends it to the database (Replica, since it’s a read)
- Jose doesn’t see the transaction he just made (because it hasn’t been copied to the read replica)
In this scenario everything went fine but Jose is not seeing the transaction he just made in his transaction history. This situation is usually referred to as eventual consistency. The system is in a consistent state, but the replica doesn’t have up-to-date information. When the replication catches up, both databases will be in sync.
This might seem like an undesirable situation, but in a lot of cases, the scalability gains justify this drawback. In the scenario above, it might be easy to add a message telling Jose that a transaction might take some time to reflect on his statement so he is not surprised.
A different configuration that comes with the challenges previously mentioned plus some of it’s own is the master-master configuration:
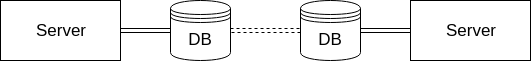
In this configuration there are two master DBs. Both of them can receive reads and writes equally. These two databases communicate asynchronously to propagate changes from one to the other. This configuration has the advantage that if one of the DBs goes down, the system can continue functioning by connecting to the other DB.
Being able to continue functioning when one of your DBs is down is a great benefit, but it also comes with some issues that might be unacceptable for some systems. Lets look at an example again:
- Jose has $10 in his account
- Jose uses these $10 to buy a burrito
- System receives the request and sends it to master1
- The database records the transaction and his balance is updated to $0
- Later Jose gets hungry again and buys one taco for $5
- System receives the request and sends it to master2
- Master2 thinks Jose’s balance is $10, so it goes ahead with the transaction
Here, the system accidentally allowed Jose to spend more money than he had in his account, so the system got to an inconsistent state. When the two databases try to sync, they will happily replicate both transactions without noticing any problem. Another problem might come when we try to synchronize Jose’s balance. One of the masters things the balance is $0 and the other things it is $5 (And they are both wrong), so how does the system decide which balance to use? A smart system would probably set the balance to -$5, and the damage would be controlled, but most likely the database won’t be able to figure this out by itself. What some database do in this scenario is keep the balance with the highest timestamp (in this case $5 because it happened later).
For a financial system like the one in my example this sounds disastrous, but there are other scenarios where it is more important for the system to be available than it is for it to be accurate, so this configuration could be used.
Conclusion
I went briefly through some examples of distributed systems and their benefits and drawbacks. There are more possible setups for stateful distributed systems that I didn’t cover in this article that you might want to take a look at. Namely, leaderless replication is a hot topic lately and I will try to write an article explaining a little about how it works.
design_patterns mysql