A while ago I wrote an article about mutexes in C++. I explained how they solve the problem of race conditions by allowing only one thread to access data simultaneously.
A read-write mutex (also known: readers-writer, shared-exclusive, multiple-readers/single-writer, mrsw) is a specialization of a mutex that allows for greater performance in a scenario where reads are more frequent than writes.
We can see how a shared mutex can be more performant in an example with multiple readers:
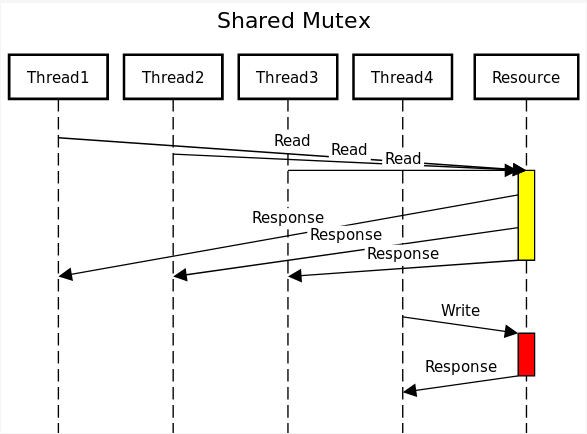
The image shows how multiple readers can access the same resource at the same time, but when a writer has the resource, nobody else can access it. If we were using a regular mutex, the program would run slower because all threads would have to wait for the mutex:
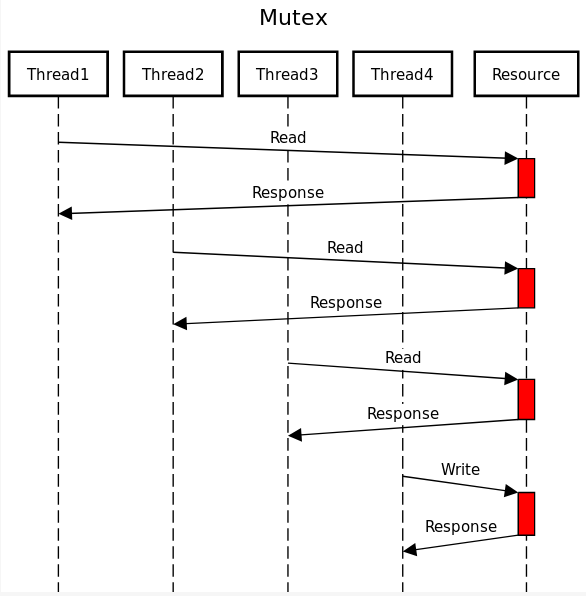
Using shared_mutex
C++17 introduced a shared_mutex implementation that is now available in most C++ compilers.
While a regular mutex exposes 3 methods: lock, unlock and try_lock, a shared_mutex adds 3 more: lock_shared, unlock_shared, try_lock_shared. The first 3 methods work exactly the same as in a regular mutex. i.e. If a mutex is locked, all other threads will wait until it is unlocked. The shared versions are a little more complicated.
Allowing readers to always lock a shared mutex even if there are writers waiting could result in writes waiting forever, so the implementation of shared_mutex uses a special algorithm that lets the programmer use it without having to think about this problem. There is one scenario that can be esily explained: If there is no thread calling lock ever, all the threads calling lock_shared will be allowed to proceed without ever having to wait.
Let’s look at an example with multiple readers and one writer that uses a regular mutex:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#include <iostream>
#include <thread>
#include <mutex>
int value = 0;
std::mutex mutex;
// Reads the value and sets v to that value
void readValue(int& v) {
mutex.lock();
// Simulate some latency
std::this_thread::sleep_for(std::chrono::seconds(1));
v = value;
mutex.unlock();
}
// Sets value to v
void setValue(int v) {
mutex.lock();
// Simulate some latency
std::this_thread::sleep_for(std::chrono::seconds(1));
value = v;
mutex.unlock();
}
int main() {
int read1;
int read2;
int read3;
std::thread t1(readValue, std::ref(read1));
std::thread t2(readValue, std::ref(read2));
std::thread t3(readValue, std::ref(read3));
std::thread t4(setValue, 1);
t1.join();
t2.join();
t3.join();
t4.join();
std::cout << read1 << "\n";
std::cout << read2 << "\n";
std::cout << read3 << "\n";
std::cout << value << "\n";
}
We can compile the code with this command:
1
g++ regular-mutex.cpp -std=c++11 -pthread -o regular-mutex
If we time the execution of this program, we will see that it takes around 4 seconds, because each thread takes around 1 second to execute:
1
2
3
4
5
6
7
8
9
$ time ./regular-mutex
0
0
0
1
real 0m4.006s
user 0m0.006s
sys 0m0.000s
Let’s optimize this code by using a shared_mutex:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#include <iostream>
#include <thread>
#include <shared_mutex>
int value = 0;
std::shared_mutex mutex;
// Reads the value and sets v to that value
void readValue(int& v) {
mutex.lock_shared();
// Simulate some latency
std::this_thread::sleep_for(std::chrono::seconds(1));
v = value;
mutex.unlock_shared();
}
// Sets value to v
void setValue(int v) {
mutex.lock();
// Simulate some latency
std::this_thread::sleep_for(std::chrono::seconds(1));
value = v;
mutex.unlock();
}
int main() {
int read1;
int read2;
int read3;
std::thread t1(readValue, std::ref(read1));
std::thread t2(readValue, std::ref(read2));
std::thread t3(readValue, std::ref(read3));
std::thread t4(setValue, 1);
t1.join();
t2.join();
t3.join();
t4.join();
std::cout << read1 << "\n";
std::cout << read2 << "\n";
std::cout << read3 << "\n";
std::cout << value << "\n";
}
The code is pretty much the same. We just changed the type of the mutex from std::mutex to std::shared_mutex and used lock_shared and unlock_shared for the read path. To compile this code we need to use C++17 and at least version 6.1 of gcc compiler:
1
g++ shared-mutex.cpp -std=c++17 -pthread -o shared-mutex
After executing this code, we can see that now it takes 2 seconds instead of 4:
1
2
3
4
5
6
7
8
9
$ time ./shared-mutex
0
0
0
1
real 0m2.004s
user 0m0.004s
sys 0m0.000s
The reason this version is faster is because threads t1, t2 and t3 can access the data at the same time. The only thread that will be waiting for 1 second is t4.
Lock guards
In a previous article where I introduced mutexes, I also introduced lock guards as a way to safely lock mutexes. Using a lock guard guarantees that a mutex will be unlocked when the lock guard goes out of scope. This prevents mistakes where mutexes are not unlocked because there was an exeption or the programmer forgot to unlock it in all code paths.
We can’t use std::lock_guard on a shared mutex because it doesn’t know about lock_shared and unlock_shared. Instead, there is a shared_lock that works similar to lock_guard but uses lock_shared and unlock_shared instead of lock and unlock:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
#include <iostream>
#include <thread>
#include <shared_mutex>
int value = 0;
std::shared_mutex mutex;
// Reads the value and sets v to that value
void readValue(int& v) {
std::shared_lock<std::shared_mutex> g(mutex);
// Simulate some latency
std::this_thread::sleep_for(std::chrono::seconds(1));
v = value;
}
// Sets value to v
void setValue(int v) {
std::lock_guard<std::shared_mutex> g(mutex);
// Simulate some latency
std::this_thread::sleep_for(std::chrono::seconds(1));
value = v;
}
int main()
{
int read1;
int read2;
int read3;
std::thread t1(readValue, std::ref(read1));
std::thread t2(readValue, std::ref(read2));
std::thread t3(readValue, std::ref(read3));
std::thread t4(setValue, 1);
t1.join();
t2.join();
t3.join();
t4.join();
std::cout << read1 << "\n";
std::cout << read2 << "\n";
std::cout << read3 << "\n";
std::cout << value << "\n";
}
The program remains pretty much the same. The only difference is that we use guards instead of manually locking and unlocking the mutexes. It is important that shared_lock is only used on read paths or it could result in data insconsistency.
c++ programming design_patterns