In previous articles, I explored how to write concurrent code using threads, how to communicate between threads using futures, async, packaged tasks and promises, how to avoid race conditions using mutexes, and other related topics. This article is going to go a little higher level and explore some things to consider when designing a concurrent system.
Why use concurrency?
Before I started working with C++, I used to write software in PHP, JavaScript, Ruby, etc. When I wrote software on those languages, I didn’t need to worry about concurrency, why do I need to worry now?
When I was writing web applications in PHP, I didn’t have to worry about threads or mutexes. I received a request, maybe got some data from a database, did some calculations and returned a result. Why can’t life continue to be that easy?
One of the reasons PHP is so simple, is because somebody else took care of the complexity for us. All the variables used by PHP while processing a request are created only for that request and destroyed after the result is sent back to the caller. There is no shared data between requests, so no mutexes are necessary. The application might have some shared data in the form of a database, but we send a request, get a response and continue with life. How come we didn’t need mutexes here? The answer is that the database engine abstracted that from us. Most likely the database engine uses mutexes internally to be able to do things concurrently, but we don’t need to worry about that.
Modern CPUs are achieving greater performance not by adding Gigahertz, but by adding cores. If we have a computer with multiple cores, but we write a program that can only process one request at a time, we would be wasting cores that we could be using to serve more users. For this reason, PHP applications usually put apache (or something similar) in front of them. Apache is another piece of software that abstracts complexity from us. It will process multiple requests in different threads, so the CPU cores are not wasted.
In essense concurrency is necessary, but it can sometimes be abstracted away. In this post I assume we are writing software at the abstraction level of a database engine as opposed to the web application.
How many threads?
Choosing how many threads a program should use is not trivial. A CPU with a single core can only execute one program at a time, but in practice, a user could be doing multiple things at the same time in such computer (e.g. Listening to music and writing a document). The way this is achieved is by context switching. The Operating System allows a process to run for some time; After the time has passed, all the state is saved and it gives a time slot to a different process. This is done so fast that users don’t notice.
A problem with context switching is that it has a considerable overhead. If context switching is done too often, the system can become really slow. How did computers solve this? They added more cores. The more cores you have, the less often you need to context switch, and the more time you spend doing useful work. The trick is to find the balance between the number cores and the number of threads.
It might be tempting to think that we should have the same number of threads as the number cores in the system, but things are not that simple. It is unlikely that the application we are writing is going to be the only thing using our CPU. At least we will have the OS also running in that machine, and most likely a few daemons taking care of different tasks.
Another problem is that threads might not be doing any actual work at some points in time. They might be waiting to retrieve some data from disk, or waiting for a mutex to be available. If this happens, it would probably be desirable to have the thread be context switched and use that CPU core to do something useful. When threads spend a lot of time waiting, to a point where the system is unacceptably slow, it is said that such system has high contention.
So, what can we do? Sadly, there is no golden rule to find the right number of threads for your system, the best thing we can do is guess and measure. What to measure? You probably want to measure the CPU (all the cores in the CPU). It is ok to have high CPU usage, but you want to leave some room for peaks or emergencies. Having 100% CPU usage all the time is not good. You also want to monitor the memory usage of your system. Threads require memory, the more threads you create, the more memory used.
Thread pools
It is common for concurrent application to need a lot of threads (more than the number of cores), because threads will spend a good amount of time waiting for a resource (mutex, disk, etc). For this reason, we need a way to manage threads efficiently.
Let’s imagine we have to design a web server. We can do something like this: start a program that will listen for URLs in a specific port. Whenever we receive a request, we start a thread that will process that request. By starting a new thread to process each request, we are able to process more than one request at a time.

We would need a mechanism for the main thread to be able to continue receiving requests while waiting for a result, but let’s ignore that detail for now.
There are a couple of problems with this approach. One of them is that we could end up creating too many threads, which would end up making the system slow. We can prevent this by setting a limit in the number of threads this program creates. The other problem is that thread creation has an overhead. If the time it takes to generate a response for a request is short, it is possible that the overhead of creating a thread is a factor that slows down the server.
A solution to this problem is thread pools. If a program uses a thread pool, it will start by creating a set of threads even if there is no work for them to do. In a simple scenario, the number of threads is static (More sofisticated thread pools could have a dynamic number of threads). The threads will wait in the pool until there is work to do; When there is work, we can just give it to the pool and it will be assigned to an available thread or put in a queue until a thread becomes available.
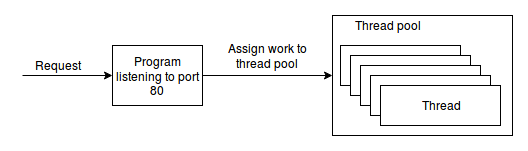
Now that we know what a thread pool is, let’s see how we can use one.
Thread pool example
Currently there is no C++ standard library that provides a thread pool, so we have to create our own. How the thread pool works and its interface will probably depend on what we need for our program.
Assuming we are building a web server, we would need it to do this:
- Start a thread pool with the same number of threads as cores in the machine
- Main thread will listen on port 9999
- Every time a request is received, we will submit the request to the thread pool
- Whenever the thread from the thread pool finishes, we’ll send a response back
- If the request is canceled or lost, we’ll tell the thread running the task to stop
These requirements might seem simple, but we will need to use different techniques to build this server. There are some design desicions we need to make before we can start writing code.
Sending the response back
One of the biggest challenges of this server is that a request will be received on the main thread, but it will be processed in a different thread, and we need a way to send a response back to the caller. Two ideas came to my mind to deal with this:
Forward the socket- One thing we can do is, after creating a socket, we can pass it to the thread, and the thread taskes care of writing the response to the socket.Pass a response to the main thread- We could use condition variables as a notification mechanism to know when a thread has finished processing a request and promises to retrieve the response from the main thread.
Creating a Synchronization mechanism using condition variables and promises might become too complicated, so we’ll use the first option.
A socket is represented by a file descriptor (an int), so the function signature for our worker will be:
1
void processRequest(const int fd, const std::string request);
The response will be sent directly to the socket from within the worker, so the function doesn’t need to return anything. fd is the file descriptor of the socket. request will be a string containing the message in the request.
The thread pool
The thread pool will consist of a group of threads that will do work when there is work to do, but will wait when there is no work to do. A good way to have threads wait for something to happen is using a condition variables.
Every time we receive a request, we will send the request to our thread pool. The thread pool will add this request to a queue. Every time an element is added to the queue, a notification will be sent to the condition variable. The thread will pop a request from the queue and process it.
The interface we will use for our thread pool is going to be:
1
void queueWork(cont int, const std::string);
The main function will call this function on the thread pool and then forget about it.
The thread pool code with comments:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
// This class manages a thread pool that will process requests
class ThreadPool {
public:
ThreadPool() : done(false) {
// This returns the number of threads supported by the system. If the
// function can't figure out this information, it returns 0. 0 is not good,
// so we create at least 1
auto numberOfThreads = std::thread::hardware_concurrency();
if (numberOfThreads == 0) {
numberOfThreads = 1;
}
for (unsigned i = 0; i < numberOfThreads; ++i) {
// The threads will execute the private member `doWork`. Note that we need
// to pass a reference to the function (namespaced with the class name) as
// the first argument, and the current object as second argument
threads.push_back(std::thread(&ThreadPool::doWork, this));
}
}
// The destructor joins all the threads so the program can exit gracefully.
// This will be executed if there is any exception (e.g. creating the threads)
~ThreadPool() {
// So threads know it's time to shut down
done = true;
// Wake up all the threads, so they can finish and be joined
workQueueConditionVariable.notify_all();
for (auto& thread : threads) {
if (thread.joinable()) {
thread.join();
}
}
}
// This function will be called by the server every time there is a request
// that needs to be processed by the thread pool
void queueWork(int fd, std::string& request) {
// Grab the mutex
std::lock_guard<std::mutex> g(workQueueMutex);
// Push the request to the queue
workQueue.push(std::pair<int, std::string>(fd, request));
// Notify one thread that there are requests to process
workQueueConditionVariable.notify_one();
}
private:
// This condition variable is used for the threads to wait until there is work
// to do
std::condition_variable_any workQueueConditionVariable;
// We store the threads in a vector, so we can later stop them gracefully
std::vector<std::thread> threads;
// Mutex to protect workQueue
std::mutex workQueueMutex;
// Queue of requests waiting to be processed
std::queue<std::pair<int, std::string>> workQueue;
// This will be set to true when the thread pool is shutting down. This tells
// the threads to stop looping and finish
bool done;
// Function used by the threads to grab work from the queue
void doWork() {
// Loop while the queue is not destructing
while (!done) {
std::pair<int, std::string> request;
// Create a scope, so we don't lock the queue for longer than necessary
{
std::unique_lock<std::mutex> g(workQueueMutex);
workQueueConditionVariable.wait(g, [&]{
// Only wake up if there are elements in the queue or the program is
// shutting down
return !workQueue.empty() || done;
});
// If we are shutting down exit witout trying to process more work
if (done) {
break;
}
request = workQueue.front();
workQueue.pop();
}
processRequest(request);
}
}
void processRequest(const std::pair<int, std::string>) {
// This function will process the request and send the response back
}
};
To build the server part, I’m going to use code from my article about building a server with C++. The processRequest function won’t really do much, we’ll just add a sleep to simulate the server doing something. Let’s put it all together:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
#include <sys/socket.h> // For socket()
#include <netinet/in.h> // For sockaddr_in
#include <cstdlib> // For exit() and EXIT_FAILURE
#include <iostream> // For cout
#include <unistd.h> // For read
#include <thread> // std::thread
#include <vector> // std::vector
#include <queue> // std::queue
#include <mutex> // std::mutex
#include <condition_variable> // std::condition_variable
// This class manages a thread pool that will process requests
class ThreadPool {
public:
ThreadPool() : done(false) {
// This returns the number of threads supported by the system. If the
// function can't figure out this information, it returns 0. 0 is not good,
// so we create at least 1
auto numberOfThreads = std::thread::hardware_concurrency();
if (numberOfThreads == 0) {
numberOfThreads = 1;
}
for (unsigned i = 0; i < numberOfThreads; ++i) {
// The threads will execute the private member `doWork`. Note that we need
// to pass a reference to the function (namespaced with the class name) as
// the first argument, and the current object as second argument
threads.push_back(std::thread(&ThreadPool::doWork, this));
}
}
// The destructor joins all the threads so the program can exit gracefully.
// This will be executed if there is any exception (e.g. creating the threads)
~ThreadPool() {
// So threads know it's time to shut down
done = true;
// Wake up all the threads, so they can finish and be joined
workQueueConditionVariable.notify_all();
for (auto& thread : threads) {
if (thread.joinable()) {
thread.join();
}
}
}
// This function will be called by the server, every time there is a request
// that needs to be processed by the thread pool
void queueWork(int fd, std::string& request) {
// Grab the mutex
std::lock_guard<std::mutex> g(workQueueMutex);
// Push the request to the queue
workQueue.push(std::pair<int, std::string>(fd, request));
// Notify one thread that there are requests to process
workQueueConditionVariable.notify_one();
}
private:
// This condition variable is used for the threads to wait until there is work
// to do
std::condition_variable_any workQueueConditionVariable;
// We store the threads in a vector, so we can later stop them gracefully
std::vector<std::thread> threads;
// Mutex to protect workQueue
std::mutex workQueueMutex;
// Queue of requests waiting to be processed
std::queue<std::pair<int, std::string>> workQueue;
// This will be set to true when the thread pool is shutting down. This tells
// the threads to stop looping and finish
bool done;
// Function used by the threads to grab work from the queue
void doWork() {
// Loop while the queue is not destructing
while (!done) {
std::pair<int, std::string> request;
// Create a scope, so we don't lock the queue for longer than necessary
{
std::unique_lock<std::mutex> g(workQueueMutex);
workQueueConditionVariable.wait(g, [&]{
// Only wake up if there are elements in the queue or the program is
// shutting down
return !workQueue.empty() || done;
});
request = workQueue.front();
workQueue.pop();
}
processRequest(request);
}
}
void processRequest(const std::pair<int, std::string> item) {
// Pretend we are doing a lot of work
std::this_thread::sleep_for(std::chrono::seconds(5));
// Send a message to the connection
std::string response = "Good talking to you\n";
send(item.first, response.c_str(), response.size(), 0);
// Close the connection
close(item.first);
}
};
int main() {
// Create a socket
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == 0) {
std::cout << "Failed to create socket. errno: " << errno << std::endl;
exit(EXIT_FAILURE);
}
// Listen to a port
sockaddr_in sockaddr;
sockaddr.sin_family = AF_INET;
sockaddr.sin_addr.s_addr = INADDR_ANY;
sockaddr.sin_port = htons(9999);
if (bind(sockfd, (struct sockaddr*)&sockaddr, sizeof(sockaddr)) < 0) {
std::cout << "Failed to bind to port 9999. errno: " << errno << std::endl;
exit(EXIT_FAILURE);
}
// Start listening
if (listen(sockfd, 10) < 0) {
std::cout << "Failed to listen on socket. errno: " << errno << std::endl;
exit(EXIT_FAILURE);
}
auto tp = ThreadPool();
while (true) {
// Grab a connection from the queue
auto addrlen = sizeof(sockaddr);
int connection = accept(sockfd, (struct sockaddr*)&sockaddr, (socklen_t*)&addrlen);
if (connection < 0) {
std::cout << "Failed to grab connection. errno: " << errno << std::endl;
exit(EXIT_FAILURE);
}
// Read from the connection
char buffer[100];
auto bytesRead = read(connection, buffer, 100);
std::string request = buffer;
// Add some work to the queue
tp.queueWork(connection, request);
}
close(sockfd);
}
Going back to our list of requirements, there is one point we are missing:
- Start a thread pool with the same number of threads as cores in the machine
- Main thread will listen on port 9999
- Every time a request is received, we will submit the request to the thread pool
- Whenever the thread from the thread pool finishes, we’ll send a response back
- If the request is canceled or lost, we’ll tell the thread running the task to stop
We haven’t done anything to deal with lost connections. Let’s take a look at that point.
It turns out that stopping a thread when a connection is lost is not that simple. There is really no way to tell a C++ function to stop what it’s doing, so the only way to do it is to add checkpoints inside the function where we check if we have lost the connection.
Furthermore, in TCP, there is no easy way to know if a connection was lost. If your program needs to do this, you will most likely have to implement your own health-check mechanism.
Because processRequest doesn’t actually do much right now, we don’t have places to put checkpoints, but it would look something like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
void processRequest(const std::pair<int, std::string> item) {
// Do some work
std::this_thread::sleep_for(std::chrono::seconds(5));
std::cout << "Did some work" << std::endl;
// Stop if we lost the connection
std::string hc = "Checking health\n";
auto err = send(item.first, hc.c_str(), hc.size(), MSG_NOSIGNAL);
if (err < 0) {
std::cout << "Lost connection. Aborting. " << errno << std::endl;
return;
}
// Do more work
std::this_thread::sleep_for(std::chrono::seconds(5));
std::cout << "Did more work" << std::endl;
// Send a message to the connection
std::string response = "Good talking to you\n";
err = send(item.first, response.c_str(), response.size(), MSG_NOSIGNAL);
if (err < 0) {
std::cout << "Lost connection. Aborting. " << errno << std::endl;
return;
}
// Close the connection
close(item.first);
std::cout << "closed" << std::endl;
}
While writing this code, I stumbled into a few interesting things. In this example I send a Checking health message to the client to verify it is still there. One thing I noticed here is that the call to send might succeed even if the client connection has been lost. This is probably because TCP doesn’t yet know that the client has disconnected.
Another interesting thing that happened while testing was that my program was crashing after calling send. This happened because a SIGPIPE signal is sent to the process when a message is sent to a socket that has been closed. To prevent this signal from being emitted, I added MSG_NOSIGNAL to the send calls and crashing was prevented.
c++ programming design_patterns