In a past post I wrote about distributed systems, but I intentionally omitted the subject of leaderless replication since I consider it a topic that deserves a little more focus.
In this post I’m going to explore how a leaderless system works and explain a little about how the Raft algorithm helps us achieve consensus.
Leaderless replication
As the name suggests, there are no leaders (or masters) in a leaderless setup. In this configuration all instances can receive reads and writes. If you read my previous post, you might be thinking that this sounds like master-master replication, but it is actually very different.
I mentioned two main problems in a master-master setup: Replication lag when you write to one master and then read from the other, and conflicts when you modify the same record in both masters and they try to sync. Leaderless replication doesn’t have these problems (it has others that I’ll explore soon). On top of not having those problems, a leaderless system can stay up even when instances are down (like the master-master configuration).
How do we achieve consistent data with no leaders?
The trick with a leaderless setup is that clients send a request to all nodes, instead of just one (like done in master-master). If everything goes well, this would mean that all nodes in our system will have the same value because the same requests are being sent to each node. Lets look at how this works:
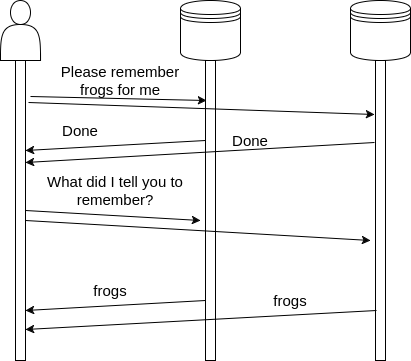
Of course, things won’t always work perfectly, so lets look at how problems are solved.
Consensus
Consensus is a technique in which a group of processes agree on a value. Although consensus can be used in many contexts, I’m going to continue my examples in terms of databases.
Consensus generally speaking is when a group of people reach an agreement. Usually the agreement is reached when most of the people lean towards one of the options. The keyword here is MOST. If there was a discussion being held between 6 people to decide if a building is going to be painted blue or green, and 3 people voted for blue and 3 for green, then a consensus wouldn’t be reached. People would argue with each other trying to convince someone from the other side that their option is better. If any one person changes their mind then we could end up with something like 4 green 2 blue, in which case the group could decide to use green since the majority decided on that color.
Why is there a disagreement in our system?
One of the goals of a leaderless system is to be able to tolerate node failures. When a node fails it is not able to record writes, so it is possible that it doesn’t know the correct state of the system (even though it thinks it does). Since we want the system to continue working even when there are failures, we let the client proceed even when it doesn’t receive an acknowledgement from all nodes.
Lets look at an example:
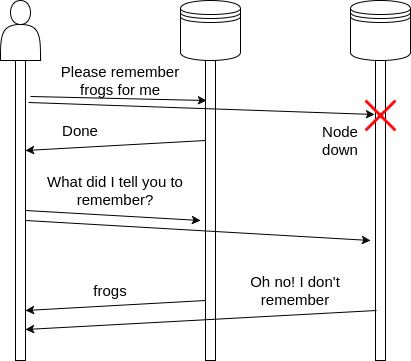
Now that we know how disagreement can arise, lets look at how we solve it. In the example above, we have two node, so both nodes would have to agree all the time. Since we want our system to tolerate failures, we can add another node, so consensus can be reached with only two machines. In this scenario, the client must be configured to know that all it needs is two nodes with the same result to consider an agreement:
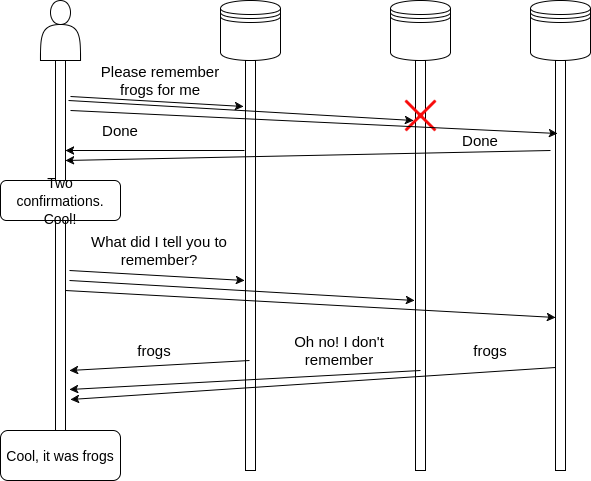
We can see here that the client was able to save and retrieve information even when one node was down at the time of writing. The problem now is that one of the nodes is out of sync with the others. How do we fix this? One option is to have the client tell the node what is the correct value. Another option could be to have a background process in charge of synchronizing nodes that have incorrect values.
Because nodes can go down and come up again at any point in time, it is possible that the majority is actually wrong. To prevent the majority from giving an incorrect value to the client, values are also versioned on each of the nodes.
To illustrate this we need a cluster with 5 nodes (3 is the majority). We will assume they already have one value on them (value: frogs, version: 1) and go from there:

Now we have an unfortunate situation where we wrote to 3 nodes, but two of them went down when we tried to read. At the end we got two wrong results and the right one. In this scenario the majority of the results were wrong, but because we require 3 results to make a decision, we are sure that at least one of them will have the right value (The one with the latest version).
Although I have tried to show some of the properties of a leaderless configuration that uses consensus, because of the amount of nodes we have, we also have an explosion of possible error scenarios. For this reason, researchers have come up with specific consensus algorithms that take care of some of the possible issues.
Raft
I’m not going to go into a lot of depth into raft, because there is a very good explanation in the raft algorithm’s website.
Before we start looking at how the algorithm works, lets look at why we might want to use it in the first place:
- Failure tolerance: Being a leaderless system using consensus, it guarantees that as long as the majority of nodes are up, the system can keep running
- Consistency: The cluster will always return the latest state or an error (if not enough nodes are up). No replication lag
- Allows cluster changes: Changes in cluster configuration (number of nodes in the cluster) can be made without losing availability
- Easy to understand: Raft claims to be easier to understand and implement than other consensus algorithms out there
Lets now look a little at how this is achieved.
The algorithm is divided in sub-problems to make it easier to understand: Leader election, log replication and safety. The algorithm covers other sections, but I’m not going to cover them in this post.
Leader election
In my consensus example above, the client talks directly to all nodes and is responsible of making sure the consensus condition is met. Raft in the other hand uses leader election and makes the leader responsible for the consensus condition.
Wait! weren’t we talking about leaderless replication? Although the Raft algorithm has a leader, the leader is dynamic and can change at any time. If the leader goes down for any reason, a new leader will come up very fast and the system will go back to normal. Let’s look at how a leader comes to be.
At the beginning of time all nodes will be on term 0 (This is just a number that increases by 1 on each voting stage) and there will be no leader (all nodes are followers). All followers expect to receive heartbeat requests from the leader periodically. If they don’t receive a request after some time (election timeout), then it becomes time for an election.
Because at the beginning there is no leader, the election timeout will be reached by one of the nodes (The timeout has some randomness on it, so it could be any node). When the timeout is reached, the follower becomes a candidate and increments its term by one (term 1). It then votes for itself and asks the other nodes to vote for it.
At the other side, the nodes will receive a request asking them to vote for the candidate containing the term number. If the term of the follower is lower than the term of the candidate, then the follower will accept and give a vote. If the candidate receives a majority of votes then it becomes the leader. After becoming the leader it starts sending heartbeats to all the followers to prevent another election from taking place.
The scenario just covered is the happy scenario, but there are other things that can happen during an election. If a candidate receives a heartbeat during an election and the term included in the heartbeat is higher than it’s current term. The candidate will recognize the request as coming from a leader and will stop the election. At this point it will transition back to follower and update it’s term to the term received in the heartbeat.
Another scenario is that the candidate doesn’t win the election. This happens if for some reason it doesn’t receive a majority of votes. In this case a timeout will trigger and it will try again.
Log replication
What we want to get from this system is a reliable state machine. Once there is a leader, clients can start interacting with this state machine by sending request to it. The way raft makes sure that the state machine can be replicated to all the nodes is by using an append only log where entries are recorded before being applied to the state machine. This log is actually the one that is replicated and needs to be kept consistent. The state machine is just the result of applying all the actions in the log.
This image shows how the happy path would look like:
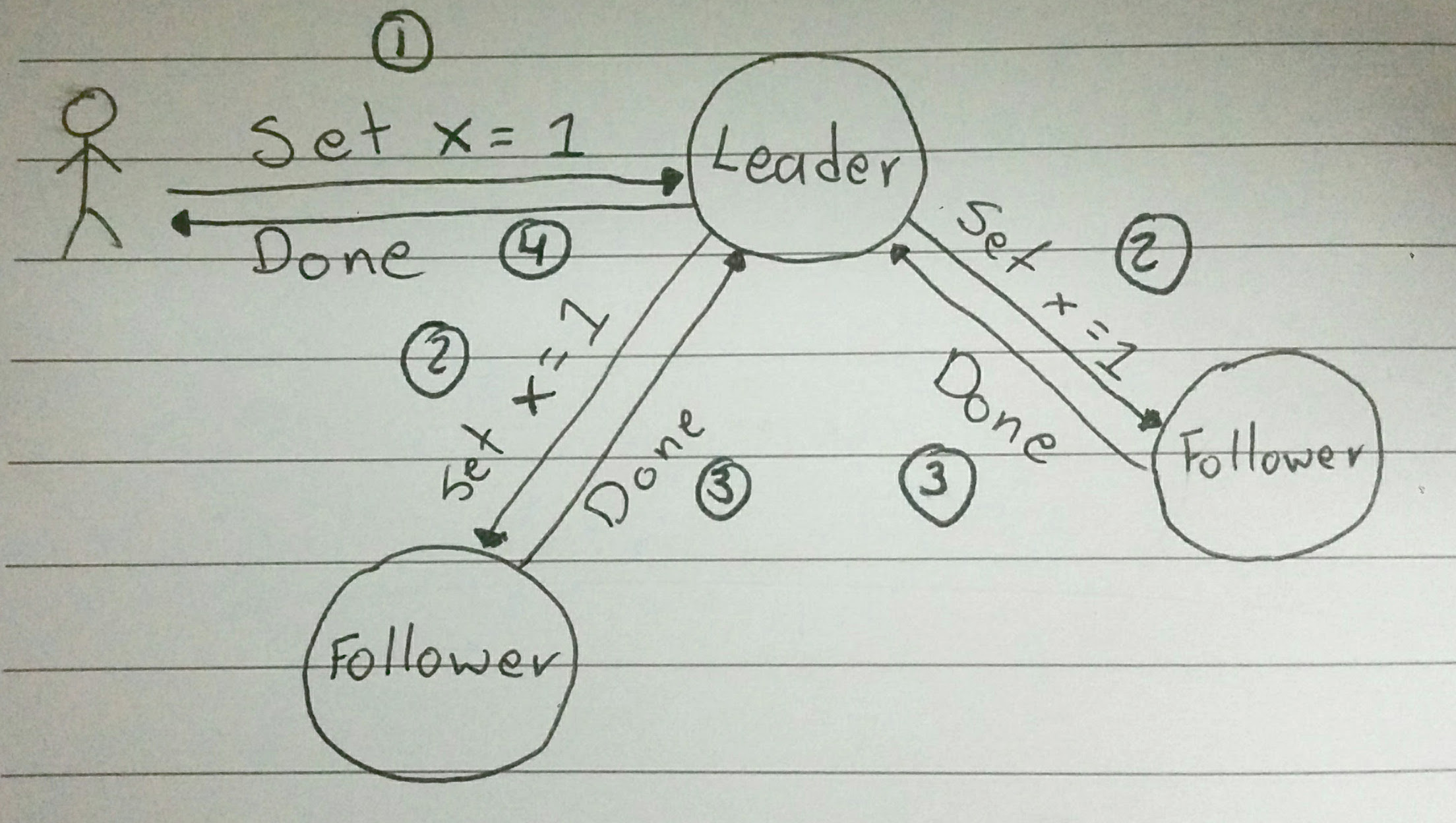
The image shows the order of the actions but it lacks detail about what actually happens in the log. So I’ll try to explain it here. First of all, lets assume this is the first request ever, so the log is empty. This is the state of the log on each of the nodes:
1
2
3
Leader: []
Follower 1: []
Follower 2: []
My representation of the log is probably not accurate, but the concept is the same. When a the request is received by the leader (1), the state will change:
1
2
3
4
5
Leader: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
Follower 1: []
Follower 2: []
Then the leader will forward the request (including the term and index) to the followers (2):
1
2
3
4
5
6
7
8
9
Leader: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
Follower 1: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
Follower 2: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
And the followers will tell the leader that everything went well (3) and the leader will commit the entry:
1
2
3
4
5
6
7
8
9
Leader: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 1: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
Follower 2: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
Finally the leader will reply to the client saying that everything went well. On the next heartbeat, the leader will tell the followers what is the latest committed entry so they can replicate:
1
2
3
4
5
6
7
8
9
Leader: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 1: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 2: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
If one of the followers goes down the algorithm will continue as usual as long as the leader can contact the majority of followers. There are a few scenarios that can cause some trouble. We’ll cover them in the next section.
Safety
I’m not going to cover all the possible states where the protocol ensures safety, because they are all well covered in their website. I’m just going to cover one unlikely scenario to demonstrate that the protocol works even in uncommon situations.
Lets look at one of the states from my previous example (But we’ll add a few more followers). The leader has committed an entry to it’s log and sent an acknowledgement to the client:
1
2
3
4
5
6
7
8
9
10
11
Leader: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 1: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
Follower 2: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
Follower 3: []
Follower 4: []
In this scenario follower 3 and 4 haven’t replied (maybe they were down). But since the leader already got the majority to save the log entry it goes ahead and commits it. Before the leader can send a heartbeat to the followers with the new committed state, it dies. What happens now?
The first thing that will happen is a new election process. Lets say follower 4 becomes a candidate. In this scenario, follower 4 will vote for itself, and follower 3 will also vote for it. Follower 1 and 2 won’t vote for it because their log is ahead of that of follower 4. Since follower 4 didn’t get at least 3 votes (the majority), the process repeats.
This time follower 1 becomes a candidate. Since follower 2 has the same log entries (index and term), it will issue the vote. Since follower 4 and 3 are behind, they will also issue their vote. Now follower 1 is the new leader.
As a new leader, it will see that all other nodes are behind and will commit it’s uncommitted entry:
1
2
3
4
5
6
7
8
9
10
11
Leader: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 1 (New leader): [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 2: [
{action: 'set x = 2', committed: false, term: 1, index: 0}
]
Follower 3: []
Follower 4: []
It will continue to send heartbeats to all nodes until they all catch up and have the same log:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Leader: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 1 (New leader): [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 2: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 3: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
Follower 4: [
{action: 'set x = 2', committed: true, term: 1, index: 0}
]
At this point our cluster is in a stable state again and it’s able to function as normal. There are many more ways in which the cluster can fail, but as long as the majority of nodes are up, the algorithm guarantees that the cluster will be able to make progress. If you are curious to know more, the paper on the algorithm’s website is very well written and easy to understand.
computer_science algorithms