IPv6 has been an Internet Standard since July 2017. Although I had heard of it since far back, I never had to know much about it until now. In this post I’m going to explain what are some of the differences between IPv4 (The previous and most widely used standard) and IPv6.
Address space
Probably the most commonly known reason behind IPv6 is that we were going to run out of IPv4 addresses soon. An IPv4 address looks like this: 192.168.100.255. In binary it would look something like this: 11000000.10101000.1100100.11111111. That is 32 bits (2^32) which equals 4,294,967,296 values.
IPv6 addresses look a little different. They are represented by 8 groups of 4 hexadecimal digits separated by a colon. For example: 1234:5678:9abc:def1:f00d:1560:0d7a:c055. This is 2^128 different combinations which is a little more than 3*10^38. This is a very high number we’re probably not going to exhaust any time soon.
Because addresses can get very long, a few conventions have been made to make them shorter to write on paper. One of them is that leading zeros in a group can be omitted. For example:
1
2
1234:0abc:9abc:00f1:f00d:1560:0035:0001
1234:abc:9abc:f1:f00d:1560:35:1
The two addresses above are the same.
Another rule is that consecutive groups of zeros can be replaced by ::. For example:
1
2
1234:0000:0000:0000:0000:1560:ab35:cafe
1234::1560:f00d:cafe
This can only be done once in the address, otherwise it would be impossible to know what the real address refers to.
Having different ways to represent an IPv6 address in text would make it hard to grep for values in logs or perform other operations. For this reason a standard way of showing them as text exists. The rules go something like this:
- Always shorten the address as much as possible
- Never replace a single group of zeros with ::. This means that this address: 1234:0abc:0000:00f1:f00d:1560:0035:0001 would become 1234:abc:0:f1:f00d:1560:35:1
- If there are two groups where the :: rule can be used, use it in the longest section. If the two sections have the same amount of groups, use it on the leftmost side
- Always use lowercase characters
Here are some examples following those rules:
1
2
3
1234:0000:dead:0000:0000:0000:0035:cafe -> 1234:0:dead::35:cafe
1234:0000:0000:dead:0000:0000:0198:dee7 -> 1234::dead:0:0:198:dee7
f00d:0015:600d:0000:0192:0168:0001:0001 -> f00d:15:600d:0:192:168:1:1
Packet format
IPv6 changed the format of the packets from the previous version (IPv4) to allow routers to work more efficiently by needing to process less data from the headers. This means the two protocols can’t communicate between each other. For an IPv6 network to communicate with an IPv4 network there has to be a translation interface in the middle.
The IPv4 packet header looks like this:

The IPv6 packet header looks like this:
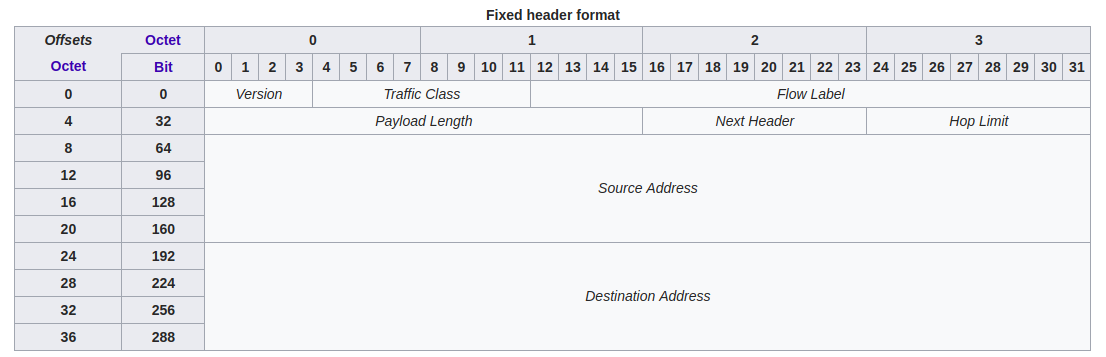
You can see from the images that IPv6 has fewer fields than IPv4 which makes it easier to process by routers. I’m not going to explain the fields in the header, but something I found interesting is that IPv6 contains no checksum field because it is assumed that lower lever layers (The link layer) will take care of error detection.
Stateless address autoconfiguration (SLAAC)
In IPv4 there is DHCP to allow a host to automatically get an address from a router. Any device with an IPv6 interface will automatically generate an address for itself even before talking to a Router. Once it detects a router it sends a prefix request, and the router responds with a prefix to use in its IP address.
As an example, lets say you have a computer with an IPv6 enabled Ethernet port. The computer will come up with a local address. This is usually the MAC address of the network interface, adding fffe in the middle. This address will be something like this: a7e5:caff:fea5:deed. It then requests a prefix from a router. Lets say this is the prefix the router advertises: 2023:ca67:7812:9809. The resulting address would be just putting these two together: 2023:ca67:7812:9809:a7e5:caff:fea5:deed.
Route aggregation
Routers in a network keep track of the routes they should direct packages through in something called a routing table. Routing tables typically use CIDR (Classless Inter-Domain Routing) to represent possible routes connected to each of their interfaces. In big networks these routing tables can become too large for routers to store. To solve this problem, route aggregation was created.
Route aggregation groups all routes in a single interface using CIDR. i.e. A subnetwork is created that groups all subnetworks connected to an interface.
If a router has two subnetworks connected to it in the same interface:
1
2
192.168.1.0/24
192.168.2.0/24
It could group them creating a subnet that covers them both:
1
192.168.0.0/22
For IPv6 this grouping happens naturally because of the way IP addresses are configured using SLACC. Because each router has its own prefix, in most scenarios the routing table will be very easy to compress.
Conclusion
This was a very shallow dive into the differences between IPv6 and IPv4. I touched the parts that I considered most important, but there are many parts I didn’t cover and there is a lot more depth that I didn’t explore in the parts I did cover.
computer_science linux networking