In the beginning of times, there were centralized version control systems (SVN and Perforce are examples). This means that there is a server somewhere that contains all our code and the history of all the changes. If someone needs to work on that codebase they do a checkout (typically of the main branch) and they will get the newest version of all the files.
If the server looks something like this (Every letter represents a different commit):
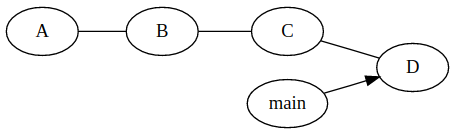
When a developer checks out main, they will get only the files at D, the commit history exists only in the server.
This has a two main disadvantages:
- It is not possible to create local branches. If a developer needs a branch they have to push it to the server
- If the server explodes, all the history is lost
Git is a distributed version control system. What this means is that a developer clones a repo before it starts working on it. The developer’s machine will contain not only the files necessary for working, but also the history of all commits. By doing this, we avoid the two problems mentioned above.
Creating a repo
If we want to create a new repo:
1
2
3
mkdir new-repo
cd new-repo
git init
Creating a commit
Once we are on a repo, the next thing we want to do is create a commit. A commit is an entry in the history of our repo. Let’s start by creating a file:
1
touch README.md
We can use git status to see the state of our repo, compared to the previous committed state:
1
2
3
4
5
6
7
8
9
10
11
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
README.md
nothing added to commit but untracked files present (use "git add" to track)
The command tells us that we are standing in master and that we have a file that is not yet being tracked.
In git, the commit process has two stages:
- Select what we want to include in the commit
- Commit the changes
When we select what we want to commit we say we are moving it to the staging area. Let’s do that:
1
git add README.md
We can see that the status changed:
1
2
3
4
5
6
7
8
9
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.md
We can now commit the change:
1
git commit -m 'Added readme file'
Looking at the history
If we want to see the list of commits from where we are standing:
1
git log
The output looks something like this:
1
2
3
4
5
6
$ git log
commit 0eba2722139ff6e91baaeb6540d4ce76c5e33d48 (HEAD -> master)
Author: User Usernikov <user@userni.kov>
Date: Thu Jun 25 21:53:16 2020 +1000
Added readme file
I personally prefer a more compact view that can be achived with this command:
1
git log --graph --all --pretty=format:'%Cred%h -%C(yellow)%d%Creset %s %Cgreen(%ci) %C(bold blue)<%an (%ae)>'
The output looks like this:
1
* 0eba272 - (HEAD -> master) Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
Because that’s a very long command, I prefer to create an alias for it. To create an alias:
1
git config --global alias.lg "log --graph --all --pretty=format:'%Cred%h -%C(yellow)%d%Creset %s %Cgreen(%ci) %C(bold blue)<%an (%ae)>'"
The command creates a git alias named lg. Now, we can use this command:
1
git lg
Branches
In the section above, we can see 0eba272 - (HEAD -> master) as part of the log ouput. There are a few important pieces of information.
0eba272- The commit hash. A unique identifier for each commitHEAD- Represents the commit where we are currently standingmaster- Branch name
From this information we can say that master is currently located at 0eba272 and our HEAD is pointing to master. Let’s create a new branch:
1
2
3
$ git branch first-branch
$ git lg
* 0eba272 - (HEAD -> master, first-branch) Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
We created a new branch, but as we can see, HEAD is still pointing to master. Let’s see what happens if we create a commit:
1
2
3
4
5
6
$ echo "Git demo" >> README.md
$ git add README.md
$ git commit -m 'Add title to readme'
$ git lg
* 0af5c64 - (HEAD -> master) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
* 0eba272 - (first-branch) Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
We can see that a new commit was created and both HEAD and master are now in that commit. Our first-branch was left behind. If we want to create a branch and move to it immediately, we can use:
1
2
3
4
$ git checkout -b second-branch
$ git lg
* 0af5c64 - (HEAD -> second-branch, master) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
* 0eba272 - (first-branch) Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
This time HEAD moved. It’s now pointing to second-branch. To switch branches:
1
2
3
4
$ git checkout first-branch
$ git lg
* 0af5c64 - (second-branch, master) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
* 0eba272 - (HEAD -> first-branch) Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
Let’s se what happens when we create a commit from here:
1
2
3
4
5
6
7
8
$ touch other.file
$ git add other.file
$ git commit -m 'Added other file'
$ git lg
* 07c7128 - (HEAD -> first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
| * 0af5c64 - (second-branch, master) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
The alias we created to see the history, has the advantage of showing us places where the history branches out. To see a list of all our branches:
1
git branch -v
Remotes
When we create a repo using git init, the repo exists only in the folder where we created it. Usually we want to host our repos in a centralized location so it acts as the source of truth for a team.
One interesting thing about centralized source code locations is that nobody works in that clone directly, it’s just a place for integration. The location where everybody pushes doesn’t have a working directory, it just keeps track of the history of all files. This is referred as a bare repo. We can create a bare repo:
1
2
3
# Assuming we are in `new-repo` folder
cd ..
git clone new-repo main-repo --bare
This creates a new folder called main-repo, that contains something very similar to new-repo/.git.
Let’s say we want to use this new clone as the souce of truth for our repo. We would need to make new-repo aware of it.
1
2
# Assuming we are in `new-repo` folder
git remote add origin ../main-repo/
The main remote for a repo, is usually called origin, which is what we called our remote. We can have multiple remotes, but it’s common to have a single one. To see our remotes and where they are hosted:
1
2
3
$ git remote -v
origin ../main-repo/ (fetch)
origin ../main-repo/ (push)
If we fetch from origin, we will get all remote branches:
1
2
3
4
5
$ git fetch origin
From ../main-repo
* [new branch] first-branch -> origin/first-branch
* [new branch] master -> origin/master
* [new branch] second-branch -> origin/second-branch
And we can see them when we list all the branches (-a includes remote branches):
1
2
3
4
5
6
7
$ git branch -av
* first-branch 07c7128 Added other file
master 0af5c64 Add title to readme
second-branch 0af5c64 Add title to readme
remotes/origin/first-branch 07c7128 Added other file
remotes/origin/master 0af5c64 Add title to readme
remotes/origin/second-branch 0af5c64 Add title to readme
It’s very common to have the master branch track origin/master. What this means is that the local master will by default be pushed to origin/master and changes from origin/master will be integrated into local master when they are pulled. Let’s make our master track origin/master:
1
2
3
4
5
$ git checkout master
Switched to branch 'master'
$ git branch -u origin/master
Branch 'master' set up to track remote branch 'master' from 'origin'.
We can now commit a change to master and push it to our remote:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$ touch file-in-master
$ git add file-in-master
$ git commit -m 'Add file-in-master'
[master 4e87837] Add file-in-master
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 file-in-master
$ git push
Counting objects: 3, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 285 bytes | 285.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To ../main-repo/
0af5c64..4e87837 master -> master
If we look at the history, we’ll see that both master and origin/master are positioned in the same place:
1
2
3
4
5
6
$ git lg
* 4e87837 - (HEAD -> master, origin/master) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - (origin/second-branch, second-branch) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
| * 07c7128 - (origin/first-branch, first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
Merging
We can see in our history that first-branch is not part of the master branch. To add it to master, we need to merge it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Assuming we are in master
$ git merge first-branch
Merge made by the 'recursive' strategy.
other.file | 0
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 other.file
$ git lg
* 118729e - (HEAD -> master) Merge branch 'first-branch' (2020-06-26 21:48:11 +1000) <User Usernikov (user@userni.kov)>
|\
| * 07c7128 - (origin/first-branch, first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
* | 4e87837 - (origin/master) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* | 0af5c64 - (origin/second-branch, second-branch) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
This created a merge commit to integrate the changes from first-branch into master. Now, all changes are part of master.
Cherry picking
Let’s imagine we didn’t do that merge and we are still at this stage:
1
2
3
4
5
* 4e87837 - (HEAD -> master, origin/master) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - (origin/second-branch, second-branch) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
| * 07c7128 - (origin/first-branch, first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
Another way we can add the first-branch commit to master is by cherry-picking it. This is useful when we have commits in different branches, but we don’t want to merge the whole branch. To do this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Assuming we are in master
$ git cherry-pick 07c7128
[master 8116729] Added other file
Date: Thu Jun 25 22:08:23 2020 +1000
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 other.file
$ git lg
* 8116729 - (HEAD -> master) Added other file (2020-06-26 21:57:14 +1000) <User Usernikov (user@userni.kov)>
* 4e87837 - (origin/master) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - (origin/second-branch, second-branch) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
| * 07c7128 - (origin/first-branch, first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
We can see that the result here is different. A copy of the commit was added to master, but first-branch is not integrated into master.
Rebasing
Rebasing is an alternative to merging that doesn’t create a merge commit. The result is similar to following these steps (We are going to call current branch the branch where we are standing and base branch the branch we are rebasing to):
- Checkout
base branch - Go back in history and find the first common commit for
base branchandcurrent branch - Cherry pick the first commit in
current branch - Cherry pick the next commit in
current branch - Keep cherry picking until there are no more commits
- Make
current banchpoint to the last cherry-picked commit - Make
base branchpoint to the same place it was pointing before the rebase
One thing to keep in mind when rebasing is that the direction of the rebase matters. Let’s again imagine we are at this stage:
1
2
3
4
5
* 4e87837 - (HEAD -> master, origin/master) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - (origin/second-branch, second-branch) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
| * 07c7128 - (origin/first-branch, first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
And we rebase from master to first-branch:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Assuming we are in master
$ git rebase first-branch
First, rewinding head to replay your work on top of it...
Applying: Add title to readme
Applying: Add file-in-master
$ git lg
* 9493b7b - (HEAD -> master) Add file-in-master (2020-06-26 22:11:13 +1000) <User Usernikov (user@userni.kov)>
* 2908379 - Add title to readme (2020-06-26 22:11:13 +1000) <User Usernikov (user@userni.kov)>
* 07c7128 - (origin/first-branch, first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
| * 4e87837 - (origin/master) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
| * 0af5c64 - (origin/second-branch, second-branch) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
This is not good because master and origin/master are now in different branches (origin/master should always be behind master). In this case, what we should have done is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
$ git checkout first-branch
Switched to branch 'first-branch'
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: Added other file
# Now, `first-branch` is ahead of `master`. We can advance `master`
$ git lg
* f2bd6e6 - (HEAD -> first-branch) Added other file (2020-06-26 22:14:03 +1000) <User Usernikov (user@userni.kov)>
* 4e87837 - (origin/master, master) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - (origin/second-branch, second-branch) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
| * 07c7128 - (origin/first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
$ git checkout master
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
$ git rebase first-branch
First, rewinding head to replay your work on top of it...
Fast-forwarded master to first-branch.
$ git lg
* f2bd6e6 - (HEAD -> master, first-branch) Added other file (2020-06-26 22:14:03 +1000) <User Usernikov (user@userni.kov)>
* 4e87837 - (origin/master) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - (origin/second-branch, second-branch) Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
| * 07c7128 - (origin/first-branch) Added other file (2020-06-25 22:08:23 +1000) <User Usernikov (user@userni.kov)>
|/
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
Deleting branches
Our history contains now a bunch of branches that we don’t need anymore. To delete them:
1
2
3
$ git branch -d first-branch second-branch
Deleted branch first-branch (was f2bd6e6).
Deleted branch second-branch (was 0af5c64).
If the branches aren’t part of master yet, the previous command won’t work. This is done to prevent us from deleting branches by mistake. If we are sure we want to delete a branch that we haven’t integrated into master, we can use:
1
$ git branch -D branch-name
We also have some branches in our remote that we aren’t going to need. Let’s delete them from there (Keep in mind that this deletes the branches from the remote, so this will affect all users of that remote):
1
2
3
4
5
6
7
8
9
10
11
12
13
$ git push origin :second-branch
To ../main-repo/
- [deleted] second-branch
$ git push origin :first-branch
To ../main-repo/
- [deleted] first-branch
$ git lg
* f2bd6e6 - (HEAD -> master) Added other file (2020-06-26 22:14:03 +1000) <User Usernikov (user@userni.kov)>
* 4e87837 - (origin/master, origin/HEAD) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
Getting changes from remotes
So far we have been using our repo as if there was only one person using it. In real life, there might be multiple people working on the same repo. In the last section we left with our master branch ahead of origin/master:
1
2
3
4
* f2bd6e6 - (HEAD -> master) Added other file (2020-06-26 22:14:03 +1000) <User Usernikov (user@userni.kov)>
* 4e87837 - (origin/master, origin/HEAD) Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
Let’s imagine another person made a change and pushed it to origin/master before we try to push our change. When we try to push, we would get an error:
1
2
3
4
5
6
7
8
9
$ git push
To ../main-repo/
! [rejected] master -> master (fetch first)
error: failed to push some refs to '../main-repo/'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
As the error message says, we need to fetch first. Fetching means getting the latest changes from a remote. Let’s do that:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
$ git fetch origin master
remote: Counting objects: 2, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 2 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (2/2), done.
From ../main-repo
* branch master -> FETCH_HEAD
4e87837..4f243e1 master -> origin/master
$ git lg
* 4f243e1 - (origin/master, origin/HEAD) Added developer-file (2020-06-27 19:43:44 +1000) <Adrian Ancona Novelo (annovelo@amazon.com)>
| * f2bd6e6 - (HEAD -> master) Added other file (2020-06-26 22:14:03 +1000) <User Usernikov (user@userni.kov)>
|/
* 4e87837 - Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
To use the fetch command we specify the remote and the brach we want to fetch. Once we have the latest changes we can either merge or rebase so our master is ahead of origin/master.
An alternative to fetch is pull. A pull is the same as doing a fetch, followed by a merge:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
$ git pull origin master
From ../main-repo
* branch master -> FETCH_HEAD
Merge made by the 'recursive' strategy.
developer-file | 0
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 developer-file
$ git lg
* 5cd5cd7 - (HEAD -> master) Merge branch 'master' of ../main-repo (2020-06-27 19:51:16 +1000) <User Usernikov (user@userni.kov)>
|\
| * 4f243e1 - (origin/master, origin/HEAD) Added developer-file (2020-06-27 19:43:44 +1000) <Adrian Ancona Novelo (annovelo@amazon.com)>
* | f2bd6e6 - Added other file (2020-06-26 22:14:03 +1000) <User Usernikov (user@userni.kov)>
|/
* 4e87837 - Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
We can tell pull to rebase instead of merging:
1
2
3
4
5
6
7
8
9
10
11
12
$ git pull --rebase origin master
From ../main-repo
* branch master -> FETCH_HEAD
First, rewinding head to replay your work on top of it...
Applying: Added other file
$ git lg
* 555d898 - (HEAD -> master) Added other file (2020-06-27 19:54:59 +1000) <User Usernikov (user@userni.kov)>
* 4f243e1 - (origin/master, origin/HEAD) Added developer-file (2020-06-27 19:43:44 +1000) <Adrian Ancona Novelo (annovelo@amazon.com)>
* 4e87837 - Add file-in-master (2020-06-26 21:40:08 +1000) <User Usernikov (user@userni.kov)>
* 0af5c64 - Add title to readme (2020-06-25 22:03:42 +1000) <User Usernikov (user@userni.kov)>
* 0eba272 - Added readme file (2020-06-25 21:53:16 +1000) <User Usernikov (user@userni.kov)>
Conflicts
In all the previous examples we were able to merge or rebase without any conflicts. In this section I’m going to show what happens when conflicts occur. Let’s imagine we have two branches that made modifications to the same file and we want to merge them:
1
2
3
4
5
6
7
8
9
10
$ git lg
* cfa8d8b - (HEAD -> master) Added content to README (2020-06-27 21:21:30 +1000) <User Usernikov (user@userni.kov)>
| * ddb5a80 - (temp) Updated README (2020-06-27 21:20:45 +1000) <User Usernikov (user@userni.kov)>
|/
* 555d898 - Added other file (2020-06-27 19:54:59 +1000) <User Usernikov (user@userni.kov)>
$ git merge temp
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
Automatic merge failed; fix conflicts and then commit the result.
Int this case, git can’t safely merge the changes without human intervention. If we look at the status of our repo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$ git status
On branch master
Your branch is ahead of 'origin/master' by 2 commits.
(use "git push" to publish your local commits)
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
We find some information telling us our options. One option is to cancel the merge using git merge --abort, which will leave the repo in the state it was before we tried to merge. Most of the time, we will need to fix the conflicts so we can integrate our work with the origin.
In the output above, we see README.md marked as both modified. This means it has conflicts we need to fix. If we open the file we see something like this:
1
2
3
4
5
6
7
Git demo
<<<<<<< HEAD
Different content
=======
Adding some information
>>>>>>> temp
The <<<<<<<, ======= and >>>>>>> markers tell us where our conflicts are. The first section is the contents of HEAD (master) and the second section is the contents of temp. What we do in this scenario depends on us. We could delete one of the sections, combine them or keep both. In this case, we are going to keep both. We’ll modify the file to look like this:
1
2
3
4
Git demo
Adding some information
Different content
Once conflicts have been resolved we need to tell git we are done and continue the merge:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
$ git add README.md
$ git status
On branch master
Your branch is ahead of 'origin/master' by 2 commits.
(use "git push" to publish your local commits)
All conflicts fixed but you are still merging.
(use "git commit" to conclude merge)
Changes to be committed:
modified: README.md
$ git commit
[master 555c386] Merge branch 'temp'
Conflicts can appear in any situation when we are trying to integrate code. Some examples are: merge, rebase, cherry-pick. The way to deal with them is the same in any scenario.
Amending
It’s common in software development to write some code and have someone else review it. What this means is that we can end with history like this:
1
2
3
4
...
* ccccc - More fixes
* bbbbb - Fixes from code review
* aaaaa - Developed awesome feature
This makes the history hard to understand.
To avoid this problem, we can ammend changes to a commit instead of creating new commits. Amending, means adding changes to the commit currently on our HEAD. This effetively adds the new changes to the commit where we are stading without creating a new commit. Let’s say we made a commit, but realized we need to make some more changes. We can add those changes to our commit like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
$ git lg
* cfa8d8b - (HEAD -> master) Added content to README (2020-06-27 21:21:30 +1000) <User Usernikov (user@userni.kov)>
$ git status
On branch master
Your branch is up to date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
$ git add README.md
$ git commit --amend
[master 5fed73d] Added content to README
Date: Sat Jun 27 21:21:30 2020 +1000
1 file changed, 3 insertions(+)
$ git lg
* 5fed73d - (HEAD -> master) Added content to README (2020-06-27 21:55:08 +1000) <User Usernikov (user@userni.kov)>
Notice that the hash of the commit changed from cfa8d8b to 5fed73d. This is because the contents of the commit also changed.
Diffs
A diff is the difference between one version of a file (or multiple files) and another. Here are some ways we can use git diff to see the changes to our files:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# Show changes that I have made but I have not committed or staged
git diff
# Show changes that are currently in my staging area
git diff --cached
# Show changes that were made in the commit we're currently standing
git diff HEAD~
# Show changes that were made in the last two commits (from where we stand)
# This can be generalized to any number of commits
git diff HEAD~2
# Show the difference between two branches
git diff one-branch other-branch
# Show the difference between two commits
git diff 4f243e1 0af5c64
The stash
Sometimes we are working on something and we get interrupted for something that will require us to make some changes in our repo. Since we don’t want to mix the new changes with whatever we were working on before, we wan’t to save our state before we start working on something new.
One way we could do this is by creating a branch and commiting our changes to that branch. Git can do this automatically for us with stashes. If we want to save our current state, we can use:
1
git stash
The stash works like a stack. We can keep stashing things and they will go one on top of the previous one. When we want to retrieve our chnages we do:
1
git stash pop
Since stashes don’t have identifiers (like branch names), it’s best to use them only for quick things, otherwise we might forget what’s in our stash.
Rewriting history
There are going to be times when we will need to make changes to the way our history looks. Let’s say our local history looks like this:
1
2
3
4
* 833cb34 - (HEAD -> master) A not so good feature (2020-06-28 18:49:36 +1000) <User Usernikov (user@userni.kov)>
* f4b9b9a - Fix bug (2020-06-28 18:48:53 +1000) <User Usernikov (user@userni.kov)>
* b779d06 - Created awesome feature (2020-06-28 18:48:11 +1000) <User Usernikov (user@userni.kov)>
* fc35d43 - Added README.md (2020-06-28 18:47:11 +1000) <User Usernikov (user@userni.kov)>
We want to push our changes to origin, but we want commits b779d06 and f4b9b9a to be a single commit instead of two. We also don’t want to push 833cb34 yet, so we’ll remove it from this branch.
To achieve this we can create a branch where we are standing and rewrite the history of master so 833cb34 is not there and f4b9b9a is squashed into b779d06.
We start by creating a branch so we don’t lose commit 833cb34 when we rewrite the history.
1
git branch feature
We can use an interactive rebase to rewrite the history.
1
git rebase -i fc35d43
Notice that the commit I chose is one before the last commit I care about.
The command will open a window that looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
pick b779d06 Created awesome feature
pick f4b9b9a Fix bug
pick 833cb34 A not so good feature
# Rebase fc35d43..833cb34 onto fc35d43 (3 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup <commit> = like "squash", but discard this commit's log message
# x, exec <command> = run command (the rest of the line) using shell
# b, break = stop here (continue rebase later with 'git rebase --continue')
# d, drop <commit> = remove commit
# l, label <label> = label current HEAD with a name
# t, reset <label> = reset HEAD to a label
# m, merge [-C <commit> | -c <commit>] <label> [# <oneline>]
# . create a merge commit using the original merge commit's
# . message (or the oneline, if no original merge commit was
# . specified). Use -c <commit> to reword the commit message.
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
The comment at the bottom explains all the things we can do from here. For our example, we are doing the following modifications:
1
2
3
4
5
pick b779d06 Created awesome feature
f f4b9b9a Fix bug
d 833cb34 A not so good feature
...
Putting an f before f4b9b9a means that it will be squased into b779d06 (They will be made one commit). Putting a d before 833cb34 means that the commit will be deleted. After we save the changes and quit the editor, the changes will be applied.
The history now looks like this:
1
2
3
4
5
6
* 5ce1955 - (HEAD -> master) Created awesome feature (2020-06-28 19:11:53 +1000) <User Usernikov (user@userni.kov)>
| * 833cb34 - (feature) A not so good feature (2020-06-28 18:49:36 +1000) <User Usernikov (user@userni.kov)>
| * f4b9b9a - Fix bug (2020-06-28 18:48:53 +1000) <User Usernikov (user@userni.kov)>
| * b779d06 - Created awesome feature (2020-06-28 18:48:11 +1000) <User Usernikov (user@userni.kov)>
|/
* fc35d43 - Added README.md (2020-06-28 18:47:11 +1000) <User Usernikov (user@userni.kov)>
We can see that master has only one commit now. The feature branch contains all the commits we had before. If we wanted, we could move to feature and do an interactive rebase to delete f4b9b9a and b779d06, since they are already in master.
Selecting what to commit
We have so far only created commits where a single file is modified, but this is not always the case. Often we will be working on multiple files at the same time and we might want to add all of them or just some of them in a single commit.
Let’s say our repo status looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: README.md
modified: abc.cpp
Untracked files:
(use "git add <file>..." to include in what will be committed)
new-file
no changes added to commit (use "git add" and/or "git commit -a")
We have 2 modified files and a new one. We can add all the changes in all the tracked files:
1
2
3
4
5
6
7
8
9
10
11
$ git add -u
$ git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: README.md
modified: abc.cpp
Untracked files:
(use "git add <file>..." to include in what will be committed)
new-file
The previous command adds all the tracked files to the staging area, but omits untracked files. If we wanted to add all files (including untracked ones):
1
2
3
4
5
6
7
8
$ git add -A
$ git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: README.md
modified: abc.cpp
new file: new-file
There might be times when there are multiple changes in a file, but we want to commit just some of them. In this case we can add parts of a file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
$ git add -p abc.cpp
diff --git a/abc.cpp b/abc.cpp
index fcfc898..314d3bc 100644
--- a/abc.cpp
+++ b/abc.cpp
@@ -5,15 +5,18 @@ Something
Other
Other
+Adding stuff here
Other
Other
Something
Something
+Here
Something
Something
Other
Other
+And here
Other
Other
(1/1) Stage this hunk [y,n,q,a,d,s,e,?]?
We can see what each of the options means by choosing ?:
y- stage this hunkn- do not stage this hunkq- quit; do not stage this hunk or any of the remaining onesa- stage this hunk and all later hunks in the filed- do not stage this hunk or any of the later hunks in the files- split the current hunk into smaller hunkse- manually edit the current hunk?- print help
If we choose s, we will be shown a smaller hunk to decide what to do with it:
1
2
3
4
5
6
7
8
9
10
11
12
(1/1) Stage this hunk [y,n,q,a,d,s,e,?]? s
Split into 3 hunks.
@@ -5,8 +5,9 @@
Other
Other
+Adding stuff here
Other
Other
Something
Something
We can continue this process until we have selected what we want to commit.
Bisect
Imagine we are working on a software project and suddenly we get a report that a feature that was working a month ago, is suddenly not working. We look at the code, but we can’t find anything suspicious. We broke something in the last month, but we aren’t sure how.
If we find ourselves in this scenario, bisect could help us find the commit that introduced the issue.
Bisect works by performing a binary search on the commit history until we find the culprit. To start bisecting:
1
git bisect start
Next we need to find a commit where we know the bug is present and mark it as bad:
1
git bisect bad
Then we need to find a commit where we know the bug is not present. Since we know the feature was working one month ago, we can go to a commit one month back, verify the bug is not there and mark the commit as good:
1
git bisect good
After doing that, git will automatically checkout the commit in the middle of those two commits. We can then verify if the bug is there or not and mark it good or bad. When we are done, we will get a message like this:
1
2
3
4
5
6
7
8
9
10
$ git bisect good
a03db35bd0dd3987d2d822a8b2a863afadd8114b is the first bad commit
commit a03db35bd0dd3987d2d822a8b2a863afadd8114b
Author: User Usernikov <user@userni.kov>
Date: Sun Jun 28 20:14:14 2020 +1000
commit 5
README.md | 1 +
1 file changed, 1 insertion(+)
When we are done, we might want to clean our bisect history:
1
git bisect reset
In the scenario above we had to manually check each commit to verify if it’s good or bad. If there is a way to automatically validate the commit, we can use this commad:
1
git bisect run verify-commit.sh
In this case verify-commit.sh is a script that can check if the commit is good or bad. If it’s good it should exit with code 0. To use this command we have to first mark at least one commit as good and one as bad.
Undoing
We all make mistakes, luckily git helps us recover when we make those mistakes.
Something that has happened more than once is adding a bunch of files to my repo by mistake. If we want to delete all the untracked files in our repo, we can use this command (This command is not reversible, so use it with caution):
1
git clean -f
The command will delete all the untracked files in the repo.
Another thing that could happen is that something modified the files in our repo and we want to restore it to the state of our HEAD (Another dangerous command):
1
git reset --hard
One more common mistake is deleting a branch that we didn’t want to delete. In this case we can use:
1
git reflog
The command gives as output a log of all the commits where we were standing. We can then checkout that commit to recover the state at that point in time. The output looks something like this:
1
2
3
4
e595ba0 (HEAD -> master) HEAD@{0}: checkout: moving from some-branch to master
31cc940 HEAD@{1}: commit: Some cool stuff
e595ba0 (HEAD -> master) HEAD@{2}: checkout: moving from master to some-branch
...
Configuration
We used git config before to create an alias, in this section I’m going to show a few more things we can do.
We can see the current configuration with the following:
1
2
3
4
5
6
7
8
9
10
11
$ git config --list
core.editor=vim
alias.lg=log --graph --all --pretty=format:'%Cred%h -%C(yellow)%d%Creset %s %Cgreen(%ci) %C(bold blue)<%an (%ae)>'
user.email=myemail@provider.com
user.name=Some user
core.repositoryformatversion=0
core.filemode=true
core.bare=false
core.logallrefupdates=true
user.name=User Usernikov
user.email=user@userni.kov
We can see a few things there: Our default editor, the alias we added, the user name and e-mail used when we create a commit, etc.
The things we most commonly want to configure are the editor, and the user information:
1
2
3
git config --local user.name "User Usernikov"
git config --local user.email "user@userni.kov"
git config --global core.editor vim
Note the use of --local and --global. When --local is used, the configuration applies only to the current repo. If we want to apply the configuration to all repos in the machine, we use --global.
Conclusion
In this article I described the most common git commands and some not so common commands that I have found useful during my career. If you are new to git, this should cover most of your every day work and a little more.
productivity git