Kafka is advertised as a distributed event store and stream processing platform. It’s used in many companies to reliably pass information between diferent systems in ways that traditional databases were not designed to do.
Let’s start by understanding why Kafka is called an event store.
In traditional databases (MySQL, for example) we can store records inside tables. Running these queries:
1
2
3
INSERT INTO people(id, name) VALUES(111, "Carlos");
INSERT INTO people(id, name) VALUES(222, "Mario");
INSERT INTO people(id, name) VALUES(333, "Jose");
Gives us something like this:
| id | Name |
|---|---|
| 111 | Carlos |
| 222 | Mario |
| 333 | Jose |
Traditional databases allow us to search for data:
1
SELECT * FROM people WHERE id = 111;
And even update it:
1
UPDATE people SET name = 'Juan' WHERE id = 333;
Which would make our data look like this:
| id | Name |
|---|---|
| 111 | Carlos |
| 222 | Mario |
| 333 | Juan |
In Kafka we have topics instead of tables and events instead of records.
In very simple terms, we can think of Kafka as a queue (there are some nuances that we’ll cover later) where events are always appended.
Let’s say we emit these events:
1
2
3
{"topic": "people", "data": {"action": "insert", "id": "111", "name": "Carlos"}}
{"topic": "people", "data": {"action": "insert", "id": "222", "name": "Mario"}}
{"topic": "people", "data": {"action": "insert", "id": "333", "name": "Juan"}}
They can be represented as something like this:
| 0 | 1 | 2 |
|---|---|---|
| {“action”: “insert”, “id”: “111”, “name”: “Carlos”} | {“action”: “insert”, “id”: “222”, “name”: “Mario”} | {“action”: “insert”, “id”: “333”, “name”: “Juan”} |
We can see that elements in the queue have an index starting from 0 and increasing by one. This index is called the offset of the event.
We can’t perform searches in Kafka, it has only two read operations: subscribe (at a specific offset) and consume. Typically, we’ll subscribe at offset 0 and start consuming events one by one.
What good is a database if it can’t be searched?
Data is only useful if we can consume it and for a lot of use cases a relational database is a good solution.
Kafka is typically used as a source of truth that can feed information into other databases. To understand this better, let’s imagine a web store that uses MySQL.
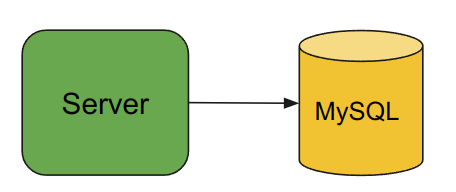
The store is working, but we want to improve the user experience by adding better search functionality. We know that Elasticsearch can help us with this, but we need to figure out how to keep the data in MySQL and Elasticsearch in sync.
One approach is to have Elasticsearch periodically read all the information in MySQL and update it’s data based on this information:
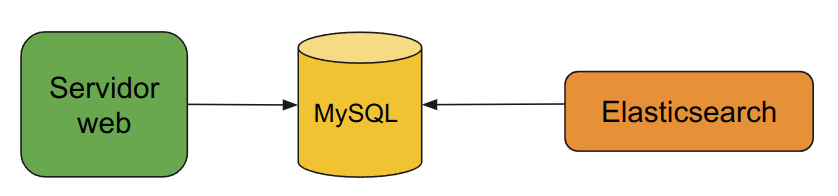
The problem with this is that Elasticsearch will have to periodically read all data in the DB, which could affect the performance of the database. A full scan could also take long so the updates will take some time to be reflected in Elasticsearch even if we do scans continuously.
This process is not only inefficient, it also means that Elasticsearch will not have up to date information right away.
We can use Kafka to keep both MySQL and Elasticsearch data in sync:
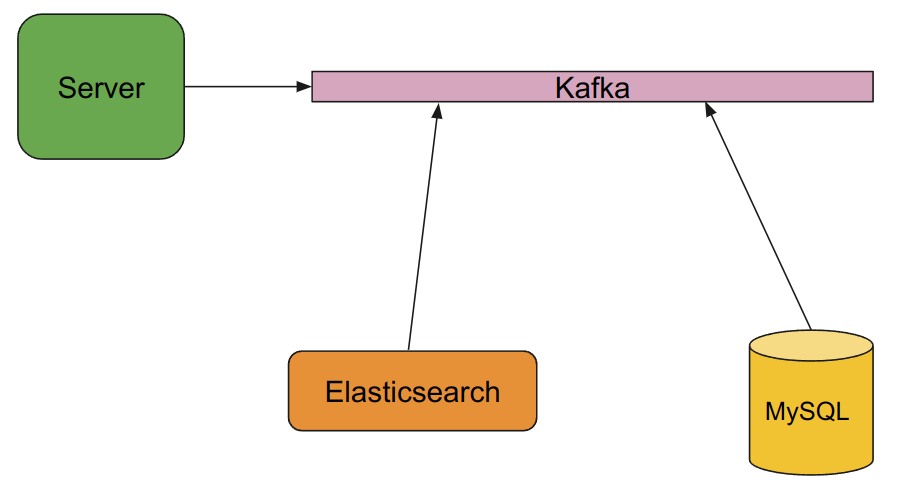
In this case, all data updates would be published to Kafka instead of being published directly to MySQL. For example, if a new product is added to the database we can add a message like this to Kafka:
1
2
3
4
5
6
7
8
9
{
"topic": "products",
"data": {
"action": "create",
"id": "34484747-de8d-4bf4-b3f8-7d00ab17edeb",
"name": "Stapler",
"stock": 10
}
}
Both Elasticsearch and MySQL will see this message and update their data. New updates will keep being added to Kafka and they will be applied to each database in real time. This means Elasticsearch will never need to read all data from MySQL since it will be applying updates at the same rate as MySQL.
Since both MySQL and Elasticsearch are consuming data at their own rate, it’s possible that there will be periods where data won’t be completely in sync, but since the updates are so small, the period of time when they will be out of date will be short compared to the previous solution.
Producers and consumers
We already saw that a topic can be represented as a queue (We’ll look into the nuances later in the article). There are two types of systems interacting with this queue: producers and consumers. Producers push events to the queue and consumers read those events.
The producing part is very simple. Every time a new event is produced, it’s added at the end of the queue.
We start with an empty products topic:

Then a producer creates a few events:
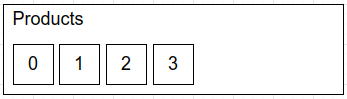
Events are added starting at offset 0. Offset numbers increase by one as new events are added. Future events will be added to the topic as they come.
There can be multiple systems producing events to the same topic. The only thing they need is the name of the topic where they want to publish the events.
Consumers need to specify a topic and an offset where they want to start consuming and they will be notified of new messages as they arrive.
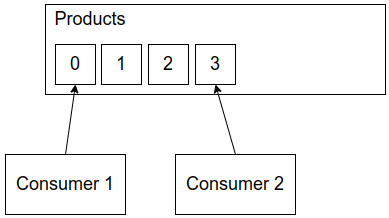
Consumer groups
A consumer group is used to “group” consumers in a way that each consumer group only consumes a message once. It’s important that a message is only consumed once, because we could have a message like this one:
1
2
3
4
5
6
7
8
9
{
"topic": "sales",
"data": {
"action": "create",
"id": "9eeed978-3e9f-40e3-889c-8cd0e0891244",
"customer": "b6dfcb42-e1a8-48c9-b857-943ae40fae88",
"total": "150.50",
}
}
If we processed it twice we could end up charging the customer more than once.
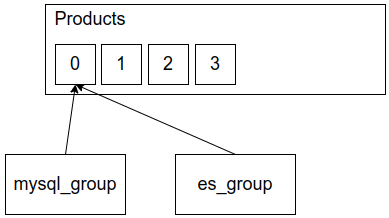
In the store example above, we had two different consumer groups. One for MySQL and another for Elasticsearch. We want to make sure that all events make it to both systems, so we need to process each event once for each of them.
Partitions
This is the part where we’ll explore the nuances of the queue analogy.
Having one queue and ensuring messages are processed only once makes the system very easy to understand, but it also acts as a bottleneck.
Imagine we have multiple producers putting events in the queue at a very high rate:
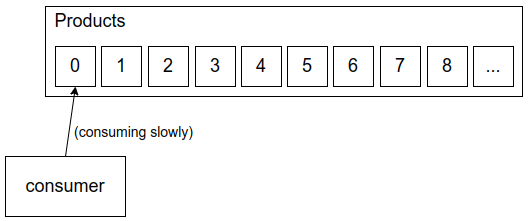
Since in the consumer side we need to ensure messages are processed in order we can’t process the events in parallel. The consumer needs to keep processing events one by one and might be left behind by the fast producers.
Kafka’s way to mitigate this problem is by creating partitions. When we have a topic with a single partition we esentially have a single queue and we can only process events one by one.
We can help split the load on a topic by having multiple partitions. This esentially means that there will be a number of queues equal to the number of partitions:

An event can be added to a partition at random or we can specify in which partition we want the event to go.
Partitions come with a very important disclaimer to consider. Events on each partition are guaranteed to be consumed in order, but order between partitions is not guaranteed.
Let’s say we have two partitions and we produce five events. The events are assigned to a partition randomly:
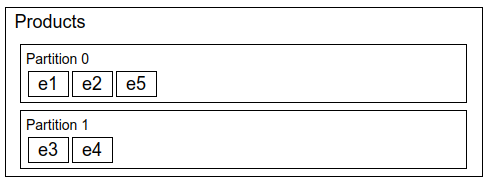
Then we have a consumer reading the events. It’s possible that it starts consuming event 3 before consuming event 1 because they are in different partitions:
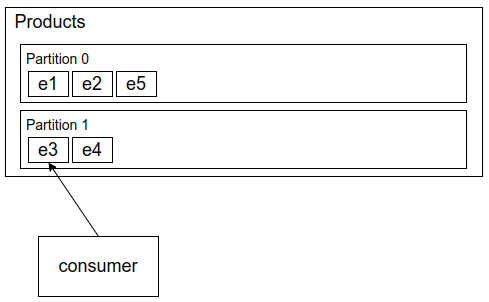
Events in the same partition will always be consumed in order so event 3 is guaranteed to be consumed before event 4.
Incorrect use of partitions can have catastrophic effects in a system. Consider a store that uses Kafka to process events related to inventory. Let’s say these events occurred:
1
2
3
{"topic": "inventory", "data": {"action": "new_product", "id": "abc-123", "stock": 2}}
{"topic": "inventory", "data": {"action": "increase_inventory", "id": "abc-123", "amount": 4}}
{"topic": "inventory", "data": {"action": "reduce_inventory", "id": "abc-123", "amount": 3}}
The events get randomly assigned to partitions:
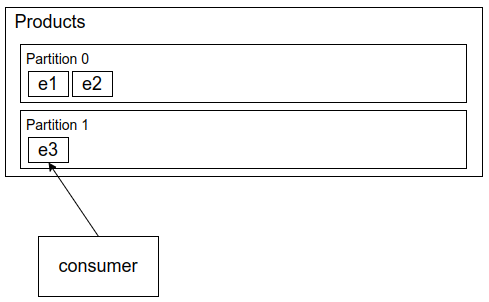
There are a few scenarios that can go wrong here:
- A consumer could start by reading event 0 in partition 1 and it would cause an error because the product with id
abc-123doesn’t exist yet. - A consumer could start by reading event 0 in partition 0 and then read event 0 on partition 1. In this case the product exists, but there is not enough inventory to reduce (2 - 3 = -1).
A way to avoid this problem would be to assign events to partitions based on the product id instead of doing it randomly, so if we had these events:
1
2
3
4
5
6
7
{"topic": "inventory", "data": {"action": "new_product", "id": "abc-123", "stock": 2}}
{"topic": "inventory", "data": {"action": "new_product", "id": "abc-999", "stock": 1}}
{"topic": "inventory", "data": {"action": "new_product", "id": "ccc-121", "stock": 4}}
{"topic": "inventory", "data": {"action": "increase_inventory", "id": "abc-123", "amount": 4}}
{"topic": "inventory", "data": {"action": "reduce_inventory", "id": "abc-123", "amount": 3}}
{"topic": "inventory", "data": {"action": "reduce_inventory", "id": "ccc-121", "amount": 2}}
{"topic": "inventory", "data": {"action": "reduce_inventory", "id": "abc-999", "amount": 1}}
Since all events for the same product are in the same partition, a product will never be in an inconsistent state.
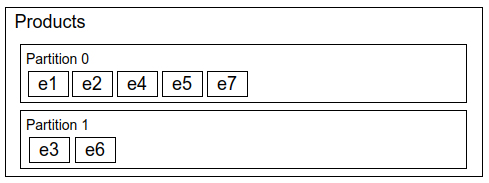
Once we design our system in a way that can support multiple partitions we can have multiple consumers assigned to a single topic. This allows us to consume events in parallel.
Since order between partitions will always be enforced, it’s not very useful to have more consumers than the number of partitions.
Manual acknowledgement of consumption
Most clients are configured to automatically acknowledge consumption of messages by default. This means that as soon as a message is read by a consumer, the next message is made available to be consumed.
This behavior is not always the right call. If our code crashes while we are processing a message, we won’t get a chance to process it again and the next message will be made available for processing.
In situations where the processing of a message can fail, we can disable auto acking. This is an example of how to do it in the python client:
1
2
3
4
5
6
conf = {
'bootstrap.servers': KAFKA,
'group.id': GROUP_ID,
'enable.auto.commit': False
}
consumer = Consumer(conf)
The option we care about is enable.auto.commit.
This means that we need to take care of acknowledging the messages ourselves. This is how it’s done in python:
1
consumer.commit(message=message)
Conclusion
This article explains some concepts that are very important to know before starting with Kafka. You can also take a look at Introduction to Kafka if you want to see some runnable code samples that illustrate all the concepts explained here.
architecture databases